

Just keep learning...
Honest insights and unfiltered learnings about almost anything related to data science and machine learning in the real world!
Follow for Updates! 🔔
Newest to Oldest ↓
The Unsung Hero of Technology
Tags: Opinion, Technology
Estimated Read Time: 4 Minutes
Spoiler: It is intelligence that is not artificial.

Image Credit: Google Search and Matt Groening
The [not so] Secret Sauce to Machine Learning
Tags: Machine Learning, Predictive Analytics, Forecasting, Useful Models, Feature Engineering, Hyperparameter Tuning
Estimated Read Time: 5 Minutes
The key ingredients for useful ML models in the real world of messy data.

Source: Tidy Modeling with R Book Club
Behind the Scenes [and Hype] of Ciquelle 1.0 ✨
Tags: Generative AI, Artificial Intelligence, Large Language Models, Agents, Streamlit, Business Intelligence
Estimated Read Time: 5 Minutes
Important considerations for building with AI from an amateur AI architect.

AI Generated Image
Meet Ciquelle [My First GenAI Bot] ✨
Tags: Generative AI, Artificial Intelligence, Flow Control, Large Language Models, Agents, Cheatsheets, Streamlit, Business Intelligence
Estimated Read Time: 5 Minutes
Ciquelle is a SQL-based Business Intelligence Copilot!
Is RAG here to stay?
Tags: Retrieval Augmented Generation, Large Language Models, Generative AI, Artificial Intelligence, Cheatsheets
Estimated Read Time: 5 Minutes
Building a retrieval framework to take LLMs to the next level!

The Anatomy of a Useful Predictive Model
Tags: Cheatsheets, Machine Learning, MLOps, Predictive Analytics, Forecasting, Useful Models, Value-Driven Outcomes
Estimated Read Time: 4 Minutes
An overview [cheatsheet] on building useful models.

[Partially] AI Generated Image
Lost in Translation
Tags: Unforgettable Storytelling, Data-Driven Decision Support, Leadership Communication, Non-Verbal Communication
Estimated Read Time: 4 Minutes
Impactful [data] stories empower good decisions.

AI Generated Image
Artificial [Emotional] Intelligence
Tags: Artificial Intelligence, Generative AI, Human Centric Design, Human-Machine Relationships, Cultural and Ethical Norms
Estimated Read Time: 4 Minutes
In the era of AI we don't just need better AI but good humans.

AI Generated Image
Data Visualization: A Lost-and-Found Art
Tags: Data Visualization, DataViz, Data Story-Telling
Estimated Read Time: 2 Minutes
If a data person creates a dashboard that doesn't tell a story, does it even exist?

AI Generated Image
Useful Predictive Modeling
Tags: Predictive Analytics, Useful Models, Value Driven Outcomes
Estimated Read Time: 2 Minutes
All models are wrong, some are useful.

AI Generated Image
The Unsung Hero of Technology
Tags: Opinion, Technology
Estimated Read Time: 4 Minutes
Author: Namrata Shetty-Anderson
Published: February 7, 2025
It is well into 2025 and it has been a while since I have written on here. No big reason, really. Just a bunch of little reasons - life, busyness, adulthood, lack of motivation… the list goes on. And the general bias towards doing the work rather than talking about it. Unless I find something worth talking about, that is not already trending all over.So here's something I articulated today that I have not quite put into words before. Something that every tech professional will probably relate to.
Troubleshooting is the underappreciated, value-enabling, unavoidable part of our jobs.
Inspiration: One of my teammates spent half his day trying to set up the Google Cloud SDK, running into authentication issues. He was setting up his new laptop, so he spent a lot of time troubleshooting set-up errors [enterprise-level installs are sometimes more complex than personal ones]. After researching and troubleshooting every single one of them, this authentication error was his last one and a puzzler. Long story short, turns out, his cache needed to be cleared. The classic "Did you try unplugging it" moment! He felt like he got no work done that day.Here's another one. It is a personal account and hence, more detailed. I installed a new package that I wanted to test out for a machine learning system I'm designing and immediately regretted it.Here's how it played out.
- Discovered a package that could be potentially relevant to my use case
- Installed the package.
- Tried using the package.
- ERROR: This package needs version > x.y.z for package [insert another existing package] and you have version a.b.c installed
- Updated the dependency. No errors.
- Restart session [paranoia?]
- Try using the package
- ERROR: This package needs version > x.y.z for package [insert another existing package] and you have version a.b.c installed [ugh!]
- Checked dependency version [still not updated… 🤔]
- Tried the same steps again [human error?]. Same outcome.
- Another [paranoid] restart of the session
- Uninstalled the dependency
- Tried reinstalling…
- Another ERROR. The gist - cannot overwrite existing dependency. [breath!]
- Tried calling dependency in my script.
- ERROR: Dependency does not exist.At this point if you feel like closing this article, I'm with you. But please stay with me, I promise there's a point. The saga continues… a quick Google search - nothing useful. I ask Gen AI - nada. Same steps that I already tried mixed with some hallucinogens.At this point, I have no choice. Time to go into the backend install folders that I'm too afraid to mess with… Also because now without the dependency, other packages [that were working fine until this whole mess] are not working either.

Source: Google Search and Matt Groening
- So I located and opened the backend folders where packages installed
- The dependency folder did infact exist in the directory [go figure!]
- But it contained only 1 file, as opposed to the multiple files and folders of a fully installed package - THERE'S THE PROBLEM! 💡
- Made a copy of the folder into another directory [the 'I might mess it up more' paranoia is real]
- Original dependency folder deleted
- Tried install.packages("dependency").✨Poof!✨Problem solved! Dependency works. Old packages work. New package works. I didn't try to dive into why all this happened - I'd already wasted 30 minutes of my life and this new package didn't even turn out to be useful for my use-case.----By themselves these are mundane occurrences. We solve such problems - Every. Single. Day. Some, we solve in a matter of minutes. Some are so big that they become roadblocks. We spend hours, we may have to reach out to others for help… All the while the stress builds up because it's taking away from the time probably blocked off to make more progress on 'real' work.Here's my point - Troubleshooting is a value enabling task. It enables work to move forward. And while it does not meet all the criteria to be considered value-add, it is hard to add value without it. And therer is learn SO MUCH to from it.It's important to find a balance between how much time is spent on solutioning versus knowing when to ask for help or finding a plan B. Like anything else, there are 'best' practices.But there's no avoiding it. It is very much part of the job and a great learning opportunity.Bake in buffers in project timelines. Learn from others' experiences - Use forums, blogs, stack overflow, Gen AI. Develop best practices, learn from experience… and maybe document some of it for the next person.Next time I spend my day fixing errors I didn’t expect, I'm going to remind myself - I did not waste time. I enabled value and probably learned something new!Just a random Friday opinion.
The [not so] Secret Sauce to Machine Learning
Tags: Machine Learning, Predictive Analytics, Forecasting, Useful Models, Feature Engineering, Hyperparameter Tuning
Estimated Read Time: 5 Minutes
Author: Namrata Shetty-Anderson
Published: September 30, 2024
Building machine learning (ML) models is a lot like cooking. With experience, you learn what works and what doesn't and you can tweak things for better results. Half the battle is knowing what's possible, which at the beginning is scary because you're so afraid of messing up.Surely, I'm not the first person to think of this analogy. Libraries and functions like recipes, parsnip, prep(), juice(), bake(), etc. already exist. Nor am I an expert ML engineer [or chef].This article is focused on two key ingredients that have helped my ML models become more useful in the real world of messy data.
[ICYMI: Useful Predictive Modeling, The Anatomy of a Useful Predictive Model]
1. Feature Engineering 🚧
Transforming raw data into meaningful features by selecting, creating and/or modifying input variables making it more suitable for the algorithms to learn from. Not only can this help improve model performance, but also manage computational resources and improve model explainability.Between scikit-learn, recipes and a host of other Python and R packages, there are many, many feature engineering techniques out there, each serving a different purpose.My most frequently used [uncomplicated] techniques include -• Transforming (splines, logs, rolls, lags, Fourier series), normalizing and standardizing numeric variables for consistent scaling
• Dummy/One Hot Encoding for categorical features to represent them as numeric values without taking into account order/ranking
• Convert flag variables (Y/N) to boolean/binary indicators
• Using principal component analysis (PCA), K-means clusters and/or hashing for high cardinality variables, like zip codes, product IDs, etc.
• Converting date/time into multiple time-series-based features (when applicable)
• Identifying and handling outliers vs key events
• Handling missing values
• Feature selection using importance scores (boruta, variable importance using caret, etc.)Important considerations -
• Thoroughly explore and understand the data before diving into feature engineering
• Seek out domain expertise to find truly causal features
• Keep it simple, avoid overfitting at all costs
• Avoid redundant/correlated features, they're just noise
2. Hyperparameter Tuning 🎛
Selecting the best set of hyperparameters i.e. settings of the model that control how much the model learns but cannot be directly estimated directly from the data.These include machine learning hyperparameters such as the number of boosting iterations, learning rate, regularization, etc. or preprocessing parameters like the number of extracted components for PCA or the number of neighbors for KNN. Not only does tuning assist with improving model performance, but it also takes the guesswork out of the process.🌈Cross-validation
Instead of relying solely on the single test-train split, cross-validation splits the data into multiple subsets of training and validation data. This ensures consistency in the model's performance and helps with selecting the best parameters through multiple performance evaluations.The two techniques I find myself using most often are -• K-Fold CV: Divides the data into k folds where the model is validated on each fold, by training on the remaining k-1 folds.
• Time Series CV: For sequential data, the training data is increased incrementally and the model is validated on the next time stamp.🔍Search Strategy
Exploring enough hyperparameter combinations is crucial for optimal performance. Too few and the model won't provide useful enough results, too many and it gets time-consuming and computationally expensive.All good ones have one main thing in common - Thoughtful choices in the experimental design of searches, making the whole process a lot easier to manage.Again, there are many tried and tested search strategies out there.1. Grid Search:
Takes a pre-defined set of parameter values, evaluates them, then chooses the best set.Regular Grids
- Combines each parameter factorially, i.e., by using all combinations of the sets.
- Can be computationally expensive to use, especially when there are many tuning parameters [but not always].
- May result in overlaps.Non-regular Grids
- Uses a sample/subset of the range of parameters using techniques like random sampling.
- May still result in overlaps.
- May not cover the whole parameter space, although larger grid sizes may cover a good portion.Space Filling Designs [My favorite ✨]
- Typically identify a set of points that span the parameter space with the smallest chance of overlap or redundancy.
- Latin hypercubes ✨, maximum entropy, maximum projection are a few options.

Source: Tidy Modeling with R Book Club
2. Iterative Search:
The search process also identifies [predicts] the next values to test. Used when grid search is not helpful. Computationally expensive.
- Bayesian Optimization: Using probabilistic models to predict better parameter settings.
- Simulated annealing [loosely based on the process in which metal cools]: Allows the search to temporarily move in the wrong direction with the potential of leading to a much better region of the parameter space over time.The best parameter set is selected by evaluating each combination using preprocessed data on the cross-validation slices..----This is by no means exhaustive. My point here is that experimentation is key. Like most good chefs, be prepared to improvise! More later.P.S. I created a custom tuning function in R that uses grid search with latin hypercube and a ✨dash of iteration✨.
- It iteratively tunes the model on a feature engineering recipe using K-fold cross-validation and a latin hypercube grid .
- The grid is restricted to the better-performing region of the parameter space with each iteration until the results can no longer be improved.
- Allows auto-tuning sets of recipes and models while combining the two techniques i.e. iterative grid search.
[Send me a message to request a free copy of the code].
DIVE DEEPER
- The tidymodels ecosystem
- The caret package
- EBook: Tidy Modeling with R
Behind the Scenes [and Hype] of Ciquelle 1.0 ✨
Tags: Generative AI, Artificial Intelligence, Large Language Models, Agents, Streamlit, Business Intelligence
Estimated Read Time: 5 Minutes
Author: Namrata Shetty-Anderson
Published: August 27, 2024
I'm as excited about Gen AI and its untapped potential as the next nerd. But when it comes to hype cycles and trends, there's always reason to tread with caution. It's important to intentionally pause the excitement for questions that may be overlooked when emotions run high.A reality check [I force myself to face] -
When deploying useful Gen AI applications that solve real-world problems, only ~10% of the effort involves building new algorithms and the fun ✨code✨ behind them. This is certainly an important piece of the puzzle, but it is also perhaps the easiest one to accomplish.A big chunk of the effort lies in getting the right systems with the right data and ensuring a robust tech stack to enable deployment and sustain scaling. The largest is for change, process and people management, the scope of which is beyond a singular blog post.As fun as it was to build my first experimental Business Intelligence Copilot, Ciquelle [ICYMI: Meet Ciquelle], I'd be remiss if I didn't point out important considerations when it comes to architecting GenAI based applications.What follows is merely a jumping-off point [and by no means exhaustive] based on my learnings and initial tests as an amateur AI architect.

Image Generated by Microsoft Copilot
Pobody's Nerfect
Just as with any other technology, there is a need for significant testing, tweaking, and updating of GenAI apps before they can be deemed ready for large-scale adoption. Expecting perfection at this stage may be premature.LLMs can and do produce inaccurate or undesirable responses. These are opportunities to learn about the gaps in the model's knowledge.• What is the version of the model being used? Newer versions are likely to perform better.
• Does the prompt provide sufficient instructions on performing the task?
• Does the prompt explain the problem well enough?
• Is there sufficient data to do the task?💡Challenge test users to break the app!
Prompt Engineering: A Necessary Skill [at least for now]
Large language models lack the ability to reason [at present] and rely on a massive corpus of training data to generate output.Agents need specific instructions. There's no shortcut to giving them all the information they need to produce acceptable results. This includes advanced prompt engineering techniques [zero-shot, few-shot, chain-of-thought… to name a few], additional information such as metadata, business rules, data dictionaries, as well as examples from the past.Ciquelle selected the wrong table before I provided metadata and schema information as part of my prompt template. The SQL generator agent also needed explicit instructions [within the prompt] on summarizing the data when the user's query warranted it.💡Google 'task specific' LLM agents… there are already working prompts and agents with high success rates out there.
This Brings Us to Accuracy… Measure to Manage
Generally speaking, one option is to ask the same example prompts multiple times to see how the response varies.Another option is to sample prompts and correct answers [say, 1K different prompts and their correct answers]. Then test the LLM on the prompts, and verify the accuracy of the response by comparing it to the correct answers. This can be done manually or using an LLM to compare the answers and give an accuracy rating. Plan to retest iteratively [can be automated] so any changes in the model's performance can be tracked.💡Ciquelle 2.0 [learning in progress] is expected to be a team of agents that can solve complex problems. A supervisor agent decides which team member(s) to route the request to and identifies if the task is completed accurately.
Production is a Long Way Ahead
Assuming the existence of a use case where Gen AI can add value [Don't be a solution chasing problems], consider starting with a local LLM/open-source model (Meta’s Llama, Hugging Face Models, Ollama, etc.) for a proof of concept.The choice between local LLMs versus cloud-based providers like OpenAI boils down to the availability of the necessary computational hardware to support the former and data privacy concerns with the latter. Owning GPUs/leveraging cloud-based GPUs [for local models] adds costs. So does every LLM call with cloud-based models.💡Balance cost vs performance by using different models for each agent depending on the use case.POCs are just that. They are built on a small amount of data and it is relatively easy to demo a reliable [incomplete] product by handpicking the best model outcomes. Scalability is a challenge. As the scale and size of the databases increase, the prompts need to be more informative and clear to provide the LLM with enough information to work well. This will significantly impact the app’s success rate.Work with SMEs from IT to establish guardrails at the enterprise level to serve as a research environment to vet out POCs, costs, etc. while ensuring data security.Ciquelle currently works with SQLite databases. More research is needed for BigQuery, PostgresSQL, MSSQL, etc. compatibility [Python has a ton of connectors for this]. Agent prompts should be modified to be language-specific for more accurate results.💡Think beyond chatbots and front-ends that are just ChatGPT wrappers and OpenAI’s models.Lastly, don't let AI overshadow BI. A lot of us are just now getting our data and forecasting models right. A solid data foundation is an obvious prerequisite that we can't afford to overlook.That's all for now.
REFERENCES
- BCG Study on Gen AI Deployment
Meet Ciquelle! My first SQL-based BI bot!! ✨
Tags: Generative AI, Artificial Intelligence, Flow Control, Large Language Models, Agents, Cheatsheets, Streamlit, Business Intelligence
Estimated Read Time: 5 Minutes
Author: Namrata Shetty-Anderson
Published: August 5, 2024
Ciquelle takes user queries through a Streamlit interface, processes these queries using natural language processing tools, interacts with a SQL database to fetch relevant data, and then visualizes the results using Plotly (if requested by the user).Ciquelle can serve as an assistant to data professionals and handle low level tasks like ad-hoc queries and visuals to answer business questions. Think of her as a new intern in training!
Ciquelle 1.0 - Demo
This [test] version of Ciquelle connects up to two [fictional] databases. The datasets available are -
Pages, The Bookstore: Sales, Customer, and Inventory data.
Wheels, The Bikestore: Bikes, Bikeshops, and Orders data.💡Fun Fact: Bookstore data was synthesized using GPT-4o without me having to write a single line of code!The user picks which database to connect to and inputs questions relevant to the data to be analyzed. Ciquelle processes the user's question to determine the appropriate SQL query or chart to generate.
How Ciquelle Works
Ciquelle comprises of several agents trained using advanced prompt engineering techniques -Routing Preprocessor Agent: Processes the initial question and decides whether the output should be a chart or a table or both.
SQL Generator Agent: Generates SQL queries based on the user's question.
Chart Instructor Agent: Serves as a Prompt Engineer to reformulate instructions from user input for the chart generator agent.
Chart Generator Agent: Takes the chart instructions and data, and generates the necessary code to produce the chart.
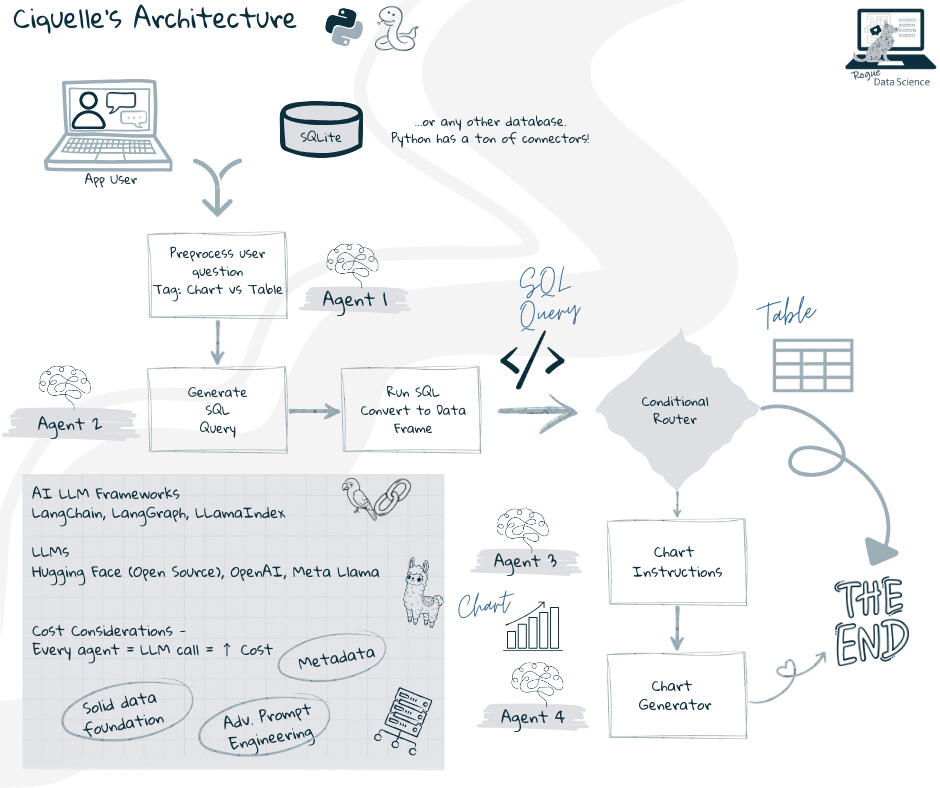
Ciquelle 1.0 - Architecture
Ciquelle's Building Blocks
Natural Language Processing with LangChain
The script leverages LangChain, an efficient framework to process user queries and generate responses. This is the secret sauce to make Ciquelle an intelligent chatbot for data visualization and analysis.Database Interaction
The app connects to a SQL database using the SQLDatabase utility from LangChain. This allows the app to execute SQL queries and retrieve data from the database tables.Query Processing and Output Parsing
User queries are processed using LangChain. The app also uses different output parsers to interpret the results of the queries and convert them into a format suitable for display.Visualization with Plotly
For visualizing data, the app uses Plotly Express, a high-level interface for Plotly. This allows the app to create interactive charts and maps based on the query results.Chat History Management
The app maintains a history of chat messages using StreamlitChatMessageHistory. This helps in keeping track of the conversation context, which can be useful for follow-up queries and maintaining a coherent interaction flow.Integration with External Models
The app leverages OpenAI's GPT-3.5 and GPT-4o per user selection but can be updated to use other LLMs as well.
-----
It is important to note that Ciquelle is a test bot that I built as a learning experiment. And this is the easy part! There are several things to be considered as we move into real world applications (enhanced capabilities driven by the business problem, cost vs value, error handling, troubleshooting, etc.).More details in future posts.Stay tuned! Ciquelle is learning and she's about to build her own data team. ✨
REFERENCES
- Documentation: Langchain
- Documentation: Streamlit
- Documentation: OpenAI
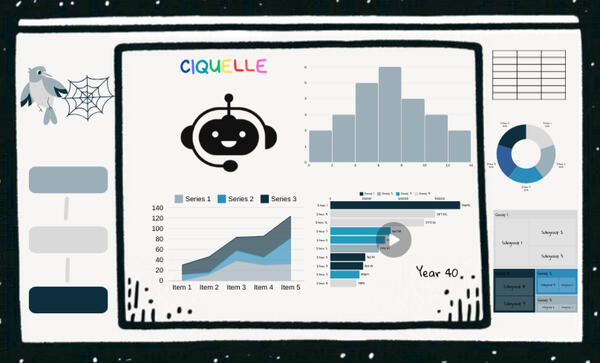
Is RAG here to stay?
Tags: Retrieval Augmented Generation, Large Language Models, Generative AI, Artificial Intelligence, Cheatsheets
Estimated Read Time: 5 Minutes
Author: Namrata Shetty-Anderson
Published: July 9, 2024
Large Language Models (LLMs) - That thing that everyone's talking about. Trained on vast amounts of data to understand and generate natural, human-like language, capable of performing a wide range of tasks from translation to summarization all the way to code assistance and automation.New buzz words are surfacing. Some sound technically daunting (Prompt Engineering, Retrieval Augmented Generation…), and others that quite honestly sound like references to sci-fi action films (transformers, hallucinations, agents… 🤖).There's excitement. Undoubtedly, this has opened up a plethora of opportunities, some so obvious that there's more than enough said about them already. Chatbots/Gen AI assistants are quickly gaining popularity, regardless of technical proficiency, industry, or even scale. Everyone wants in.And there's reason to tread with caution. The enormous computational requirements, ethical concerns around privacy and misuse, the fine line around content creation, the importance of human oversight, interpretability... How does your AI friend arrive at its conclusions? [Friend? Read more about human-machine relationships]LLMs operate as black boxes. Training them involves SUBSTANTIAL computational resources, a massive corpus of data and a deep understanding of machine learning principles. And you don't just have to loosen the purse strings, you pretty much need to cut them. [I recently learned that it can cost as much as $150K for training a 7B parameter LLM from scratch and that's considered a 'small model'? 🤯] It can easily cost millions to go from an initial pilot to development, deployment, integration and testing with additional annual recurring costs [anywhere between $8K-$25K, rough estimate] per user!LLMs are generalists. While they are trained on a vast amount of knowledge already, they are not specialized by default. They are designed to be used for general reasoning and as text engines. This makes them less effective for use cases that warrant task specific knowledge. For example, while an LLM can provide general information about dogs, but understanding the specific traits, behaviors, and care needs of different dog breeds requires specialized knowledge.Generalist black boxes become less reliable as the complexity and specificity of use cases increase. Go figure! This is where the concept of grounding comes in.
What is Grounding?
Grounding is the process of using LLMs with information that is use case specific, relevant, and not available as part of the LLM's trained knowledge. It is a way of providing additional, specific context to the model for better quality, accuracy, and relevance of the generated output.Retrieval Augmented Generation (RAG) is the primary technique for grounding. Fine tuning is another "option", I use double quotes since there are very few scenarios where this offers a positive tradeoff between output and outcome. I'd consider it a last resort, if that.
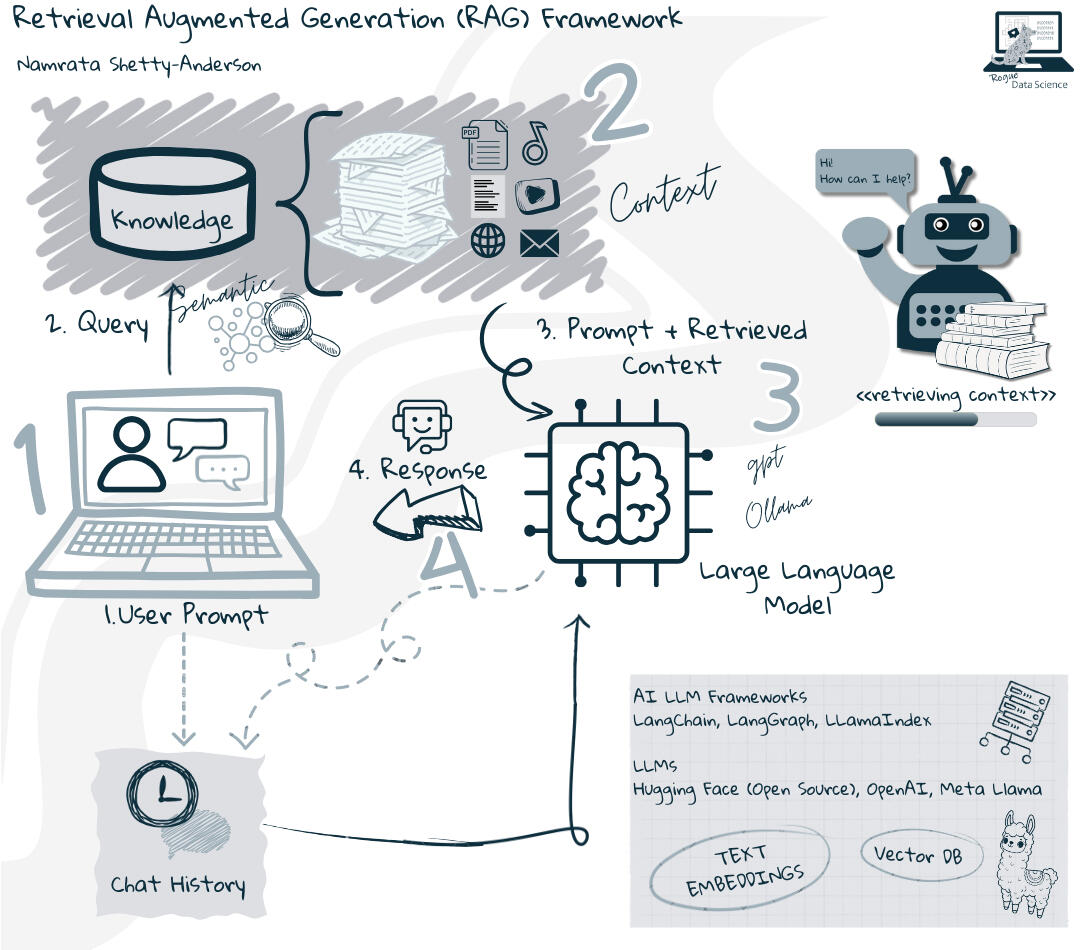
RAG Framework
What is RAG?
RAG combines LLMs with context retrieval. It involves retrieving relevant information from an external knowledge base [say, organizational documents or domain-specific knowledge] to supplement the LLM's internal knowledge base before generating a response. It extends the capabilities of LLMs without retraining the model by retrieving context. It is significantly more cost-effective than fine-tuning and improves model performance greatly.It's akin to equipping your Gen AI system with a library of textbooks to read through and answer queries.
Why RAG may be here to stay
RAG addresses several limitations of traditional LLMs:
- Accuracy: By grounding responses in external data, RAG reduces the likelihood of generating incorrect or outdated information.
- Transparency: Users can trace the source of the information, enhancing trust in the model’s outputs.
- Efficiency: The need for constant retraining of the model is significantly reduced with RAG, as it can dynamically fetch the most recent information.
- Cost-Effectiveness: It reduces computational and financial costs associated with frequent model updates.
- More Developer Control: RAG allows developers to test and enhance their chat applications.This in turn enhances reliability, scalability, and user trust.Some Use Cases [Not an exhaustive list]
- Q&A on specific knowledge (Eg. Chatbot that is a domain expert)
- Generating content with contextual awareness (Eg. GitHub Copilot references open files in VS Code)
- Contextual information retrieval using APIs (Eg. Weather or Stock information)RAG [or grounding in general] can also be used for memory and state management in multi-step generation processes (Eg. Chatbot that uses chat history for context).
How it Works
At its core, RAG operates through a combination of semantic search and generative modeling.Pre-Requisite: An external knowledge base [for context]
The first step is to create or have an external knowledge base, outside of the LLMs training dataset, to serve as contextual information. It can contain information from multiple data sources (APIs, databases, document repositories, web scraping, etc.). It is very important to load all relevant, domain specific data as part of this database. The database should be maintained with current information for retrieval.Simply put -
1. User Query: The process begins with a user query.
2. Semantic Search: The query is used to perform a semantic search [a popular but not the only technique] on an external knowledge base. [This step also emphasizes the importance of clean and well-structured data, as the quality of retrieved information directly impacts the model’s output.]
3. Retrieval: Relevant documents or data snippets are retrieved based on their semantic similarity to the query.
4. Generation: The retrieved information is then fed into the LLM, which generates a response grounded in the external data.
Real World Implementation
A solid data foundation is crucial for the success of RAG. To effectively bring RAG to your production environment, consider -
- Data Quality: Ensure that the external knowledge base is clean, well-structured, and regularly updated.
- Data Security: Implement robust data security measures to protect sensitive information and maintain user privacy.
- Infrastructure: Establish a scalable infrastructure that can handle the computational demands of semantic search and LLM generation.
- SME Involvement: Collaborate with IT experts to establish guardrails for a secure and scalable research environment for testing and validating RAG implementations.
- Cost Considerations: Costs are driven by prompt size, answer output size, the number of iterations, API calls, and the average token price... and they increase as you scale.
- Measuring Value [The tricky part]: Consider defining metrics for productivity improvement [don't forget about leakage]. Think in terms of your use case. Don't be a solution that chases problems.
Dive Deeper
If you're interested, learn more about - Semantic Search, Vector Indexing and Databases, Knowledge Graphs, Text Embeddings, LangChain.More to come on building a RAG application, scaling, and measuring cost vs value.
REFERENCES
- From Concept to Results: 5-Part On-Demand Series (Gartner)
- Microsoft Community on Grounding
- AWS on RAG
- Databricks on RAG
The Anatomy of a Useful Predictive Model
Tags: Cheatsheets, Machine Learning, MLOps, Predictive Analytics, Forecasting, Useful Models, Value-Driven Outcomes
Estimated Read Time: 4 Minutes
Author: Namrata Shetty-Anderson
Published: June 25, 2024To request a free copy of the cheat sheet, simply send me a message 🔗. Mention the cheatsheet. I'd love a brief overview of your use case!
George Box, a renowned statistician, said "All models are wrong, some are useful".Business projections need to be as useful as the impact of the decisions driven by them.Here is an overview of the elements in a useful predictive model and my cheatsheet. (💡 Future articles to dive deeper).
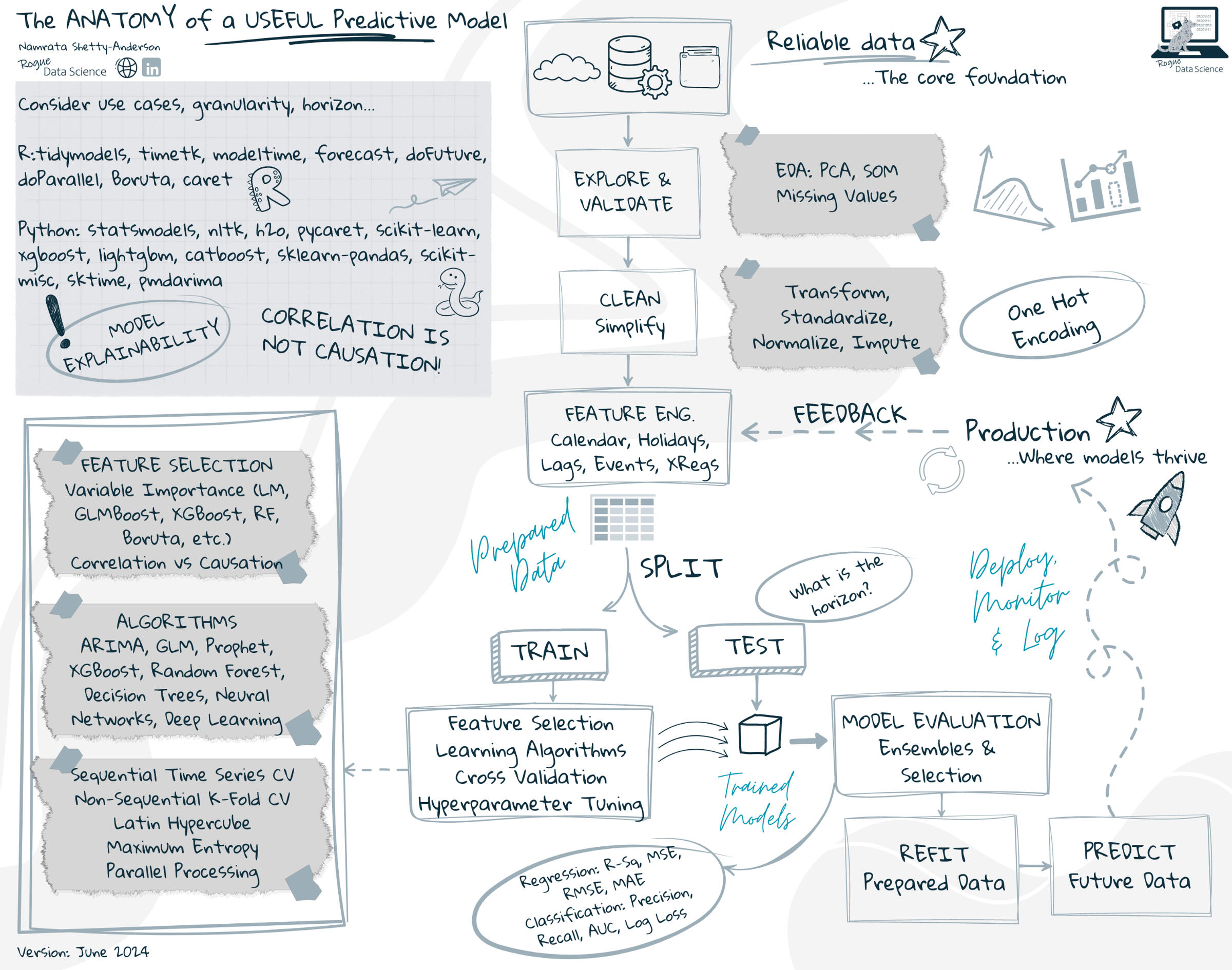
Cheatsheet: The Anatomy of a Useful Predictive Model
1. Gather reliable data
Historical or sample data, relevant features, and external predictors that will be used to train the model.
- Understand the use case.
- Span/sample size should be realistic and representative of the use case under consideration.
- Identify granularity, complexity, horizon, etc. based on the use case.
- For time series-based models, the further out your horizon, the wider the cone of probability. Choose a horizon that balances accuracy with business needs.2. Explore, validate, and clean the data
Keep relevant information, impute what's missing and needed and drop unnecessary bits.
- Look for patterns, anomalies, insights…
- Identify and address missing values
- Use transformations
- Standardize and normalize the data3. Pre-process the data
Add in relevant features that are important to the target variable. Establish causation in addition to correlation.
For example, feature engineering for time series-based models may include -
- Calendar features to capture seasonality and trends.
- Lags, Rolling Averages, and Splines.
- Knowledge and impact of key events like promotional periods or Superbowl Sunday.
- Add in movable holidays.
- Consider relevant external features like economic indicators, consumer markets, and relevant events (pandemic?).4. Split the data
- Divide data into training and testing sets.
- Good rule of thumb: The test period should at least be as long as your forecast horizon.5. Train the models
Feature Selection
- An essential step that is often overlooked. Proper feature selection prevents overfitting and ensures reliable results.
- Use packages like caret with selection algorithms based on Variable Importance Scores such as LM, GLMBoost, XGBLinear, and XGBTree.
- Boruta search is also an option.Algorithms
- Explore algorithms like Prophet, Neural Networks, XGBoost, ARIMA, NNETAR, and their boosted variants.
- Set up and fit your model specifications using frameworks like tidymodels (for R users).Hyperparameter Tuning and Cross-Validation
- Determine optimal model parameters through techniques like time-series cross-validation for sequential models and K-Fold for non-sequential models.
- Employ search strategies like 'Grid Search' to cover the parameter space efficiently.Training Workflows
- Construct a training workflow using the recipes and tuned model specifications.
- For R users, tidymodels and modeltime offer time-saving functions to achieve this. For multiple recipes and models, consider using workflow sets.6. Test, evaluate, and select the best model
- Calibrate the models on test data.
- Select top performers based on model metrics like R-Sq, RMSE, MAE, etc. (time series/regression) or precision, recall, AUC, etc. (classification).
- Combine top-performing models in an ensemble to leverage their strengths and evaluate metrics.7. Retrain the selected model on all data (instead of just training data).8. Finally, predict future values.9. Deploy to production for batch/online predictions, continuous monitoring, and logs to collect feedback to improve model performance.Important Notes -
- Don't fall in love with your model.
- Regularly bring in new data, wrangle, add features, and refit your model for updated forecasts based on model performance.
- Sometimes, doubling down on training helps - I sometimes reserve a ‘horizon’ worth of data from the modeling process entirely and use the refitted forecast to identify the best models and set thresholds.
- Model explainability is not a luxury, but a necessity. It builds stakeholder trust and allows informed decision-making. Techniques like LIME and SHAP can help.
- Deep learning models often trade off compute resources and explainability with complexity, sometimes without significant gains in model performance. Use them wisely.Remember, this is just an overview. More deep dives to come.To request a free copy of the cheat sheet, simply send me a message 🔗. Mention the cheatsheet. I'd love a brief overview of your use case!
REFERENCES
- Documentation: tidymodels
- Documentation: timetk
- Documentation: modeltime
- Book: Tidy Modeling with R
Lost in Translation
Tags: Unforgettable Storytelling, Data-Driven Decision Support, Leadership Communication, Non-Verbal Communication
Estimated Read Time: 4 Minutes
Author: Namrata Shetty-Anderson
Published: June 19, 2024
The first time Mojo and I met, she did not like me. Every time I moved, she growled, her gaze fixed as if she was ready to attack if need be. A large guard dog by nature, she was set in her senior ways and [understandably] wary of me, a complete stranger, in her space. I didn't coax nor plead, instead just sat quietly, my body language gentle, offering her my open palm as she approached me. She sniffed and paused tentatively, then finally decided to give me a chance. By our second encounter, I upgraded to a chin rub. Finally, the head pat. And the rest is history - we were soulmates until our very last day.Intent Matters - it can make or break stories.Unforgettable storytelling hinges on being mindful of how intent is perceived, just as we consciously consider how our content is coming across.We live in a world [science fair] of information overload - overhyped headlines, trending stories, the browser rabbit hole, the choice paralysis of online shopping, an avalanche of notifications between tweets, posts, likes, comments, emails, texts… and a long list of others.The human brain can process 11M bits of information every second. However, our conscious minds can process only 40 bits per second. Our brains have no choice but to take cognitive shortcuts to process, filter, and forget. This is also where unconscious bias comes into play further shaping our perceptions.

Image Generated by Microsoft Copilot
Storytelling is a crucial skill for [data] people everywhere. It is where information meets insights, weaving a compelling narrative and empowering better decision-making. We need to tell powerful stories!Of course, content matters. But emotions matter more. Our conscious minds are better at remembering information that has emotions attached to it. Stories create experience and awaken emotions. Think of an actor on stage—the emotions attached to their performance linger long after the curtain falls. Dr. Nick Morgan’s Leadercamp identifies five memorable storylines:1. The Quest: Teaches us about persistence.
2. Stranger in a Strange Land: Shows us how to cope with change.
3. Revenge: Gives us justice.
4. Rags to Riches: Comforts every person.
5. Love Story: Endorses community.Interestingly, storylines 1 and 2 cover most business situations.But when it comes to intent - it is not thought about consciously and sometimes taken for granted.Consider how our unconscious minds pick up on social cues - through mirror neurons. These extraordinary cells are fired up when we perform an action and when we observe a similar act performed by someone else. Simply put, we pick up social cues because we leak emotions to each other in the form of mirror neurons. If you've ever laughed out loud in a movie theatre at something you wouldn't by yourself, you have your mirror neurons to thank.Telling unforgettable stories is about aligning intent with content. Our non-verbal cues speak volumes - Mojo learned that she could trust me because she picked up on my cues.So whether it's our first impression at a formal presentation or a casual chat, how we walk into a room, or what we do with our hands - our demeanor immediately impacts those around us.Linguists estimate that about 30% of comprehension comes from non-verbal cues. Below are some [of the many] pointers about non-verbal cues collected from thought leaders (cited below) -- Be present. Avoid multitasking. It showcases distraction, not efficiency.- Take it easy. Breath. Smile. A stressed demeanor signals others to stay away.- Gestures serve as punctuation marks in conversations. They signal our brains to take mental note. Use them.
Use the horizontal space to convey openness. The vertical to emphasize importance.
Avoid the urge to keep your hands together [this is safety mechanism in our brain], it does not convey openness.
We lose the ability to fully see each other’s hands in virtual settings. If you're on camera, raise your hands higher so they’re visible.- Reflect more. Be aware of your own inherent biases, [we descend from the anxious members of our species who were more responsive to threats], especially in the virtual world.
We tend to assume that silence on a call implies negativity or that being off-camera is a sign of disinterest.
Remember, virtual backgrounds may make people appear two-dimensional, but they're still very much real people, with real emotions.Non-verbal cues aren’t about deception. It's not about 'getting away' with anything [most of us have a tell anyway].Instead, it is about being aware of what our cues convey unconsciously and how our biased brains perceive them. So you can tell impactful stories and also, remember some good ones.
REFERENCES
- Leadercamp: Unforgettable Storytelling by Dr. Nick Morgan
- Sol Rashidi on LinkedIn
- Understanding Unconscious Bias, NPR
- Article: What We Know Currently about Mirror Neurons by J.M. Kilner and R.N. Lemon
Artificial [Emotional] Intelligence
Tags: Artificial Intelligence, Generative AI, Human Centric Design, Human-Machine Relationships, Cultural and Ethical Norms
Estimated Read Time: 4 Minutes
Author: Namrata Shetty-Anderson
Published: June 13, 2024
My first car was a gift from my parents. My dad named it [her] Betsy and I have some great memories with that car. I might have even loved it [her]. Because years later, when I bought my own car, I didn't skip a beat before naming it [her] Betsy II. The name didn't stick for very long, but I still get a little calendar notification every time the anniversary of Betsy II's purchase passes by.To be clear, I don’t celebrate my car's 'gotcha' day or humanize it in any [other] way. It just helps remember how old it is.Humans have always anthropomorphized machines - we name our boats, our cars. I named my robot vacuum cleaner Rosie (inspired by The Jetsons). Some voice-activated home assistants can have custom names. Siri, Alexa, Cortana, Google, Bixby… the list goes on.I have listened to some really insightful and thought-provoking talks on the human aspects of [Gen] AI. Mary Mesaglio at Gartner talked about the relationships between humans and machines. Tom Gruber, the Co-Creator of Siri spoke on the Creative Confidence Podcast about the importance of human-centric design.Below are my learning notes, summarized for readability.

Image Generated by Microsoft Copilot
The concept of human-machine relationships is not new and has continued to evolve. However, it may be more vital now than ever for us to get this relationship right.This era of generative AI marks the beginning of [yet another] shift in the relationship between humans and machines. It's not just about the amazing things this cool new piece of technology can do or the profits it can garner. But it's also about setting cultural and ethical norms that shape how humans and machines relate.It is about approaching AI in a human way, with people at the center - then it can be a powerful tool that augments how we work. As AI becomes more widespread across industries, it is critical to learn the skills to harness and collaborate with AI in a humanistic, ethical, and impactful way.In short - In addition to technology and business, behavioral outcomes also need to be taken into account when considering any human-to-machine investment, including AI and Gen AI.This isn’t to say that no one is thinking about behavioral outcomes. However, generally speaking, there seems to be more confidence around the technology and business outcomes with a defined structure that encompasses accountability, value, productivity, and return on investment. On the other hand, behavioral outcomes are usually left implicit or fuzzy, and sometimes even forgotten with little to no accountability.ML/AI experts are currently in high demand i.e. Machine Experts. This may be a call for all ethicists, behavioral scientists, anthropologists, sociologists… i.e. Human Experts.This is where Technology and Human Centric Design crossover - where technical expertise and ever-evolving technology open up a myriad of possibilities and human-centric design ensures value, impact, and usefulness. [💡Human-Machine Behavioral Expert - The Role of the Future?]----
A [tiny] lens into the potential behavioral outcome of the many permutations of human-to-machine relationships -
Digital Disinhibition:
- This happens when a human behaves differently on the internet with lowered guardrails than they would in person
- Toxic Disinhibition: Anonymous trolls on social media platforms
- Intimate Disinhibition: Sharing secrets with a machine (therapy bots) instead of a humanUniversalization and Expectations:
- We tend to universalize technology and its capabilities - I always marvel at how my parents lived an internet-less childhood, and I'm pretty sure children today find it hard to imagine a life before streaming or social media
- We transfer expectations from one customer experience to another - If it's not Prime one (or two)-day shipping, I get a little sadAlgorithmic Aversion:
- This is the opposite of Digital Disinhibition
- It is the avoidance of technology because of the lack of trust in its abilities
- An example would be my husband who refuses to use Google Maps because he claims to know this city better (I'm neither denying nor confirming)Notice that we're also shifting from attention to intimacy in the human-machine relationship dynamic. [💡Are nanny bots the future?]---
So what do we do with all this information?Technology inventions always seem to outpace regulatory environments. While they catch up, it is important that we set healthy boundaries and realize the importance of this new area of responsibility.Our role is to put in place lighthouse principles and governance - What will we allow? What will need humans in the loop? What will we never/always allow? Where is our line?A good trigger to start this conversation is to ask 'How does this technology make the user feel?'. The reason people resist change is not because they are busy, it's because they don’t see how it will help them. Resistance fades when usefulness is clear.Decide what a healthy human-machine relationship looks like. Also, decide what an unhealthy human-machine relationship looks like. Focus on extending human capabilities. Be equally rigorous about behavioral, technology, and business outcomes.In the era of AI we don't just need better AI but good humans.
REFERENCES
- Gartner Webinar: What if Your Most Human-Centric Leader is a Machine? by Mary Mesaglio
- Creative Confidence Podcast: How to Get the Most Out of AI, with the Co-creator of Siri
- Implementing Effective Data Stewardship: An Open Roundtable led by Jamie Warner, Plymouth Rock Assurance and Dan Boisvert, Biogen
Data Visualization: A Lost-and-Found Art
Tags: Data Visualization, DataViz, Data Story-Telling
Estimated Read Time: 2 Minutes
Author: Namrata Shetty-Anderson
Published: June 06, 2024
"If a tree falls in a forest and no one is around to hear it, does it make a sound?". This is a popular philosophical thought experiment that raises questions about observation and perception.

Image Generated by Microsoft Copilot
Consider this -
"If a data person creates a dashboard that doesn't tell a story, does it even exist?"Being a data person is just as much an art as it is a science. The art of telling stories, answering unasked questions and ultimately creating value.Data storytelling should always be about the story and the data, not the tools used to convey them.Quite often, when ready to visualize (mined) data, our visualization toolbox is predefined for us (often by the level of comfort and skills in certain visualization software, standardized practices, and templates, etc.). This can be limiting for effective storytelling.There's a simple technique that most great data visualization artists practice. A technique that has certainly helped me become more intentional about communicating my data story.They start with a blank page. Literally.
Taking that moment to put pen to paper, brainstorm and visualize the end product without being biased by the capabilities of a pre-defined toolbox can make all the difference.Often this exercise will lead back to your existing toolbox. Then by all means, build that dashboard!But every so often, it may warrant considering alternatives - custom visuals, combining/overlaying multiple visuals, using web-based tools, or sometimes even manually putting shapes and visuals together for ad-hoc use cases.Sure, it's not 'standard' practice. But what's better?
An automated dashboard that no one understands and therefore never uses or…
An end product that is easy to consume and enables decisions to drive value.Some stories are worth breaking a few rules over.So before you spend all that time building out your elaborate dashboards, try drawing out your data story on a piece of paper. Experiment! Recognize valid exceptions.It's simple and effective!
REFERENCES
- Coursera Course: 'Business Analytics: Communicating with Data' by Kevin Hartman
- Gartner Webinar: The Power of Data Storytelling in the Realm of Gen AI by Aura Popa
- Book: Knowledge is Beautiful by David McCandless
- Wikipedia: If a tree falls in a forest and no one is around to hear it, does it make a sound?
Data Visualization: A Lost-and-Found Art
Tags: Predictive Analytics, Useful Models, Value Driven Outcomes
Estimated Read Time: 2 Minutes
Author: Namrata Shetty-Anderson
Published: May 30, 2024
Complex machine learning models, albeit smart (and so fun to build!), are not always the right predictive solution.They can be extremely powerful, and strangely cathartic. However, without the right use cases and data to back them up, they're solutions chasing problems that may never even exist. They will certainly be a great learning experience, but they might not solve the originally intended problem.

Image Generated by Microsoft Copilot
Sometimes, being a data person in the real world warrants speed over accuracy - quick but educated estimates over accurate predictions that take a long time to compute. Data emergencies are a real thing! Sure, not all deviation from the norm is a crisis. But justified emergencies are bound to show up in the real [business] world.When the inevitable happens, the impostor within creeps up.To quote the Hitchhiker's Guide - Don't panic!Projections are not meant to be set in stone. Projections are estimates for the most likely outcome knowing what we know today about the past, present, and future. The cone of probability widens as you increase complexity, granularity, horizon, etc. Internalize this, then externalize it!George Box, a renowned statistician, said "All models are wrong, some are useful". Projections need to be as useful as the impact of the decisions driven by them.I find it's always helpful to ask - "What are the projections being used for?" to trigger a value-driven outcome.Next - Identify granularity, complexity, horizon, etc. based on the use case. Maybe the use case does not warrant a complex, ML-based granular model. A simple trends-based estimate may suffice, especially if the use case has lower stakes with little to no immediate or direct impact on the business.Quick preliminary projections can always be backed with reliable numbers in the near term.Communicate! Be transparent, and set expectations on the feasibility and reliability of the outcome with business users.It's more about educating the end users on the best ways to leverage the information rather than walking them through the painstaking algorithmic black boxes.Resistance fades when usefulness is obvious!
REFERENCES
- Real-life learnings
- Book: The Hitchhiker's Guide to the Galaxy by Douglas Adams